How to Fine-Tune AI to Suit Your Writing Style
- Reading time
- 9 min read
- Written by
- by Kate

There comes a time in every writer’s life when they want to make the AI model they use to write in their voice. Sometimes a very good prompt can already help with this, but what if you want to take it a step further? This is called a fine tune, and it is a great way to make the AI model respond in a way that you want.
What is a Fine Tune?
Fine-tuning of AI models refers to the process of adjusting and retraining a model on a specific dataset to specialise its performance for a particular task or domain.
For writers, we want to encourage the AI model to write in a style more reminiscent of our own style.
Types of Fine Tune
So… what kind of fine tune models can I make? The simplest to grasp would be the “prose correction” fine tune. We will also look at a prose writing fine tune.
Prose Correction Fine Tune
Here, we can take a paragraph and “rewrite” the text, removing any AI-isms. Below is an example of my prose correction fine tune. The first sample was generated by GPT4-turbo.
Before:
Persephone tugged at a peony, observing the petals drift downwards, vanishing before they could touch the earth. Her mother, Demeter, was confronting Aphrodite (once more), the two women standing forehead to forehead as they quarrelled over a matter that didn’t concern them. Persephone rolled her eyes, her sigh of exasperation dissolving silently into the air, much like the delicate petals that had just escaped her fingers.
After:
Pulling at a peony, Persephone watched the petals fall away, disappearing before they hit the ground. Her mother was arguing with Aphrodite again, the two women practically nose to nose as they bickered over something that wasn’t their business. Persephone huffed.
You can generate the data for this fine tune in one of two ways:
- Take an AI-generated paragraph and rewrite it in your voice.
- Take a paragraph that you have written by hand, and then get the model that you usually use to write in to rephrase the paragraph. This will enable you to “pick up” the bad habits of the model.
We advise you use paragraphs that are 45+ words as in testing these gave us the best results, regardless of paragraph length.
Prose Writing Fine Tune
We can also create a beat to prose fine tune, perfect for the write interface. These beat to prose fine tunes enable us to remove AI-isms at the source, and have a model that is much closer to your voice. Think of how much time you will save editing!
Naturally, this fine tune is harder to make. We encourage you to start with the prose correction fine tune as it is easier to gather a data set.
What is Novelcrafter’s “AI Fine Tune Dataset Editor”?
For the ease of our users, we have created a simple interface to convert your data into the format that OpenAI require for fine tuning.
Think of this interface as a slightly more involved file converter - like how you would convert a jpeg to a png file, this takes your excel or raw data and converts it into the .jsonl format that OpenAI require for making their fine tune models (and other vendors too, it’s kind of become an industry standard).
We still have to put in the effort to make the dataset, this simply saves writers from needing to learn coding and the like!
You can access the AI Fine Tune Dataset Editor here: AI Fine Tune Dataset Editor.
Anatomy of a Fine Tune
Think of the fine tune layout akin to how the OpenAI playground lays everything out. You have your system message, working in the background. Then you input the user message yourself, and the assistant gives you a message in return.
In a fine tune, we manually input all three of these values, to “train” the AI to give desired results. 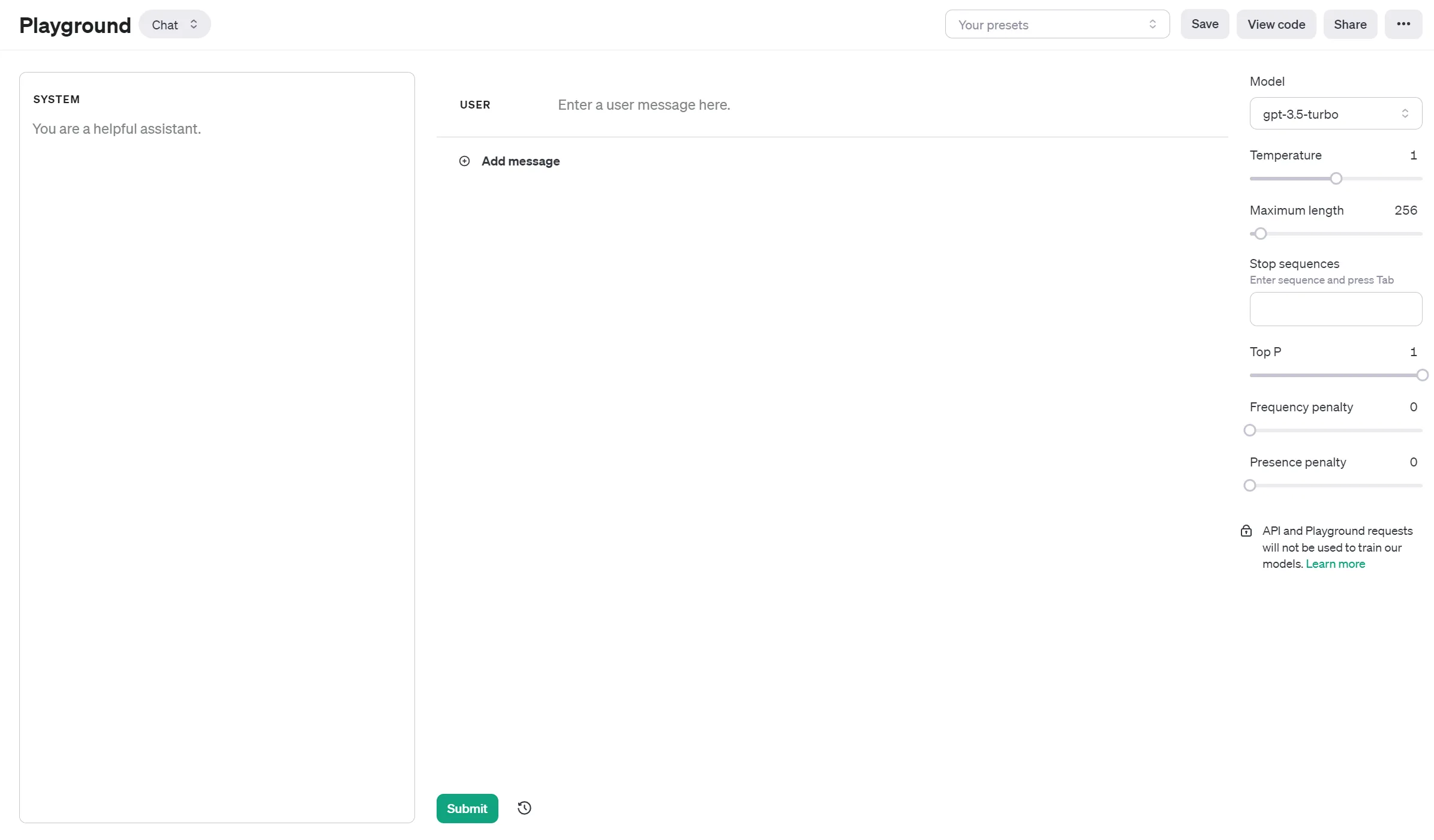
Here is the equivalent layout in the AI Fine Tune Dataset Editor: 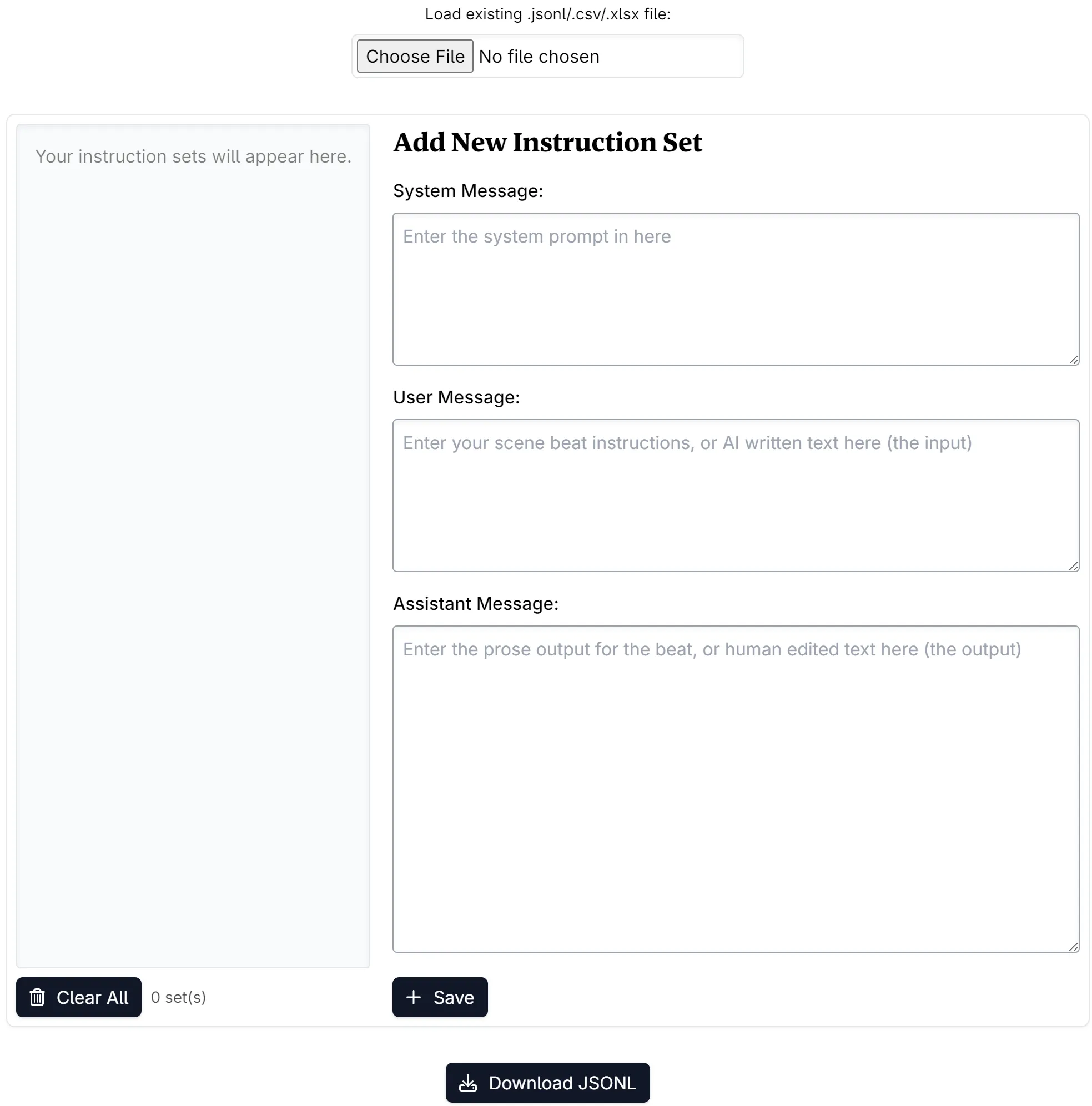
System Message
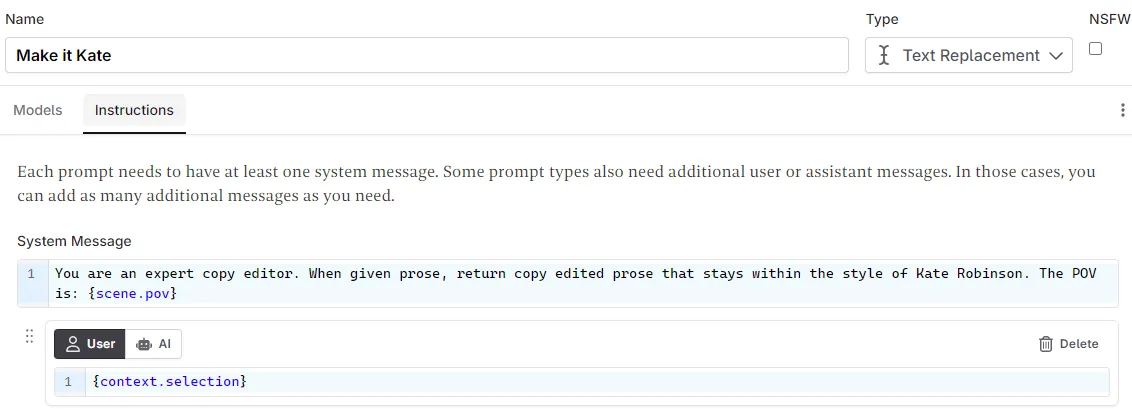
You want to keep this super simple, focusing on something that will “activate” the AI and let it know that you want to use the fine tune. Below are some examples that our users have found work for them. You don’t need hugely complex system messages, as the good habits will be built into the fine tune.
Prose correction:
You are an expert copy editor. When given prose, return copy edited prose that stays within the style of [name].
Beat to prose:
You are the [genre] author [name]. Each time I prompt you with a scene beat, write 250,000 characters based on the idea. Don’t conclude the scene on your own, follow the beat instructions closely. Don’t end with foreshadowing.
User Message
Prose correction: the AI-written prose
Persephone tugged at a peony, observing the petals drift downwards, vanishing before they could touch the earth. Her mother, Demeter, was confronting Aphrodite (once more), the two women standing forehead to forehead as they quarrelled over a matter that didn’t concern them. Persephone rolled her eyes, her sigh of exasperation dissolving silently into the air, much like the delicate petals that had just escaped her fingers.
Beat to prose: your beat. Write these beats exactly how you would write them in Novelcrafter so that you get the best results.
Johann and Aleksandra enter the tent, and see the body. Despite it looking peaceful, there are ritualistic cuts. Aleksandra hides her own markings. Johann investigates further, his thoughts racing too quickly for Aleksandra to follow.
Assistant Message
Here you will put the “ideal” response:
Prose correction: the hand-written/corrected prose
Pulling at a peony, Persephone watched the petals fall away, disappearing before they hit the ground. Her mother was arguing with Aphrodite again, the two women practically nose to nose as they bickered over something that wasn’t their business. Persephone huffed.
Beat to prose: the prose. Hand-written prose is best, however edited AI prose will get you a decent result too, provided you have edited it to match your natural voice.
‘Shall we?’ Johann lifted the flap of the tent for her. She stepped in.
The scent of wildflowers hit her. Ena’s body was surrounded by them, dried flowers placed strategically between those already planted in this garden to give the illusion of endless fields. Her hair had been whipped by the wind, but any strands weighed down by her body were well-brushed, twisted carefully in a surprisingly elegant hairstyle. A traditional Anzen style Aleksandra had a vague recollection of. Something about it all nagged at the back of her mind, a memory that she should remember, but had blocked out long ago.
Makeup had been carefully applied to Ena’s face to hide the discolouration of death. Her eyes were closed, her face relaxed and slack. Nothing to indicate that she had been in any pain when she had been killed.
Beside her, Johann’s mind was whirring, too quick for her to grasp onto a specific thought without considerable effort. He paced around the body, careful to avoid the flowers, bending over occasionally to take a closer look. Clenched in his hand was an antique looking-glass, which he occasionally lifted as he closed in on details.
She turned back to Ena, frowning. She looked almost peaceful; content. It was unnatural. Johann turned over her arm, revealing deep cuts that had been cleaned postmortem. They were long, running up from the palms to the elbow. Aleksandra tugged her own sleeves further down, hiding the cuts that lay there. Pale silver scars littered her arms, but they paled to the dark red ritual marks that she and Johann shared. She noticed Johann glancing down at his own arm, his overcoat and gloves hiding anything incriminating.
The Fine Tune Interface
When formatting within the NC fine tune interface, paste in your messages like such: 
After you hit “save” can see the entry in the sidebar to the left.
Using an Excel or Google Spreadsheet
Alternatively, you can also use Google Spreadsheet or Excel to create your dataset, and then convert it to the .jsonl format using the AI Fine Tune Dataset Editor. Simply have your first column be the system message, the second column be the user message, and the third column be the assistant message:
Then, you can export the file as a .xlsx file, or copy the data into the AI Fine Tune Dataset Editor.
You are an expert copy editor. When given prose, return copy edited prose that stays within the style of [name].
Persephone tugged at a peony, observing the petals drift downwards, vanishing before they could touch the earth. (…)
Pulling at a peony, Persephone watched the petals fall away, disappearing before they hit the ground. Her mother was arguing with Aphrodite again, (…)
This makes it much easier to also search and replace any errors in your dataset and and easily see what you have written.
Then, all you need to do is to upload the .xlx file to the AI Fine Tune Dataset Editor, and it will convert it to the correct format (.jsonl) for you.
Uploading the Dataset to OpenAI
Remember: GPT models are filtered, therefore, we want to keep the fine tune reasonably clean. If something gets rejected, it’s not the end of the world, but it’s easy enough to get 50 paragraphs that don’t have any uber violent or sexual content in.
Click “Create”
Fill out the form as follows:
- Base model: gpt-3.5-turbo-1106
- Training data: your file (Ensure that your file name has no ‘spaces’ in it or it will be rejected.). Then press upload and select.
- Validation data: none (We don’t need to use this for creative texts, this is meant for factual data)

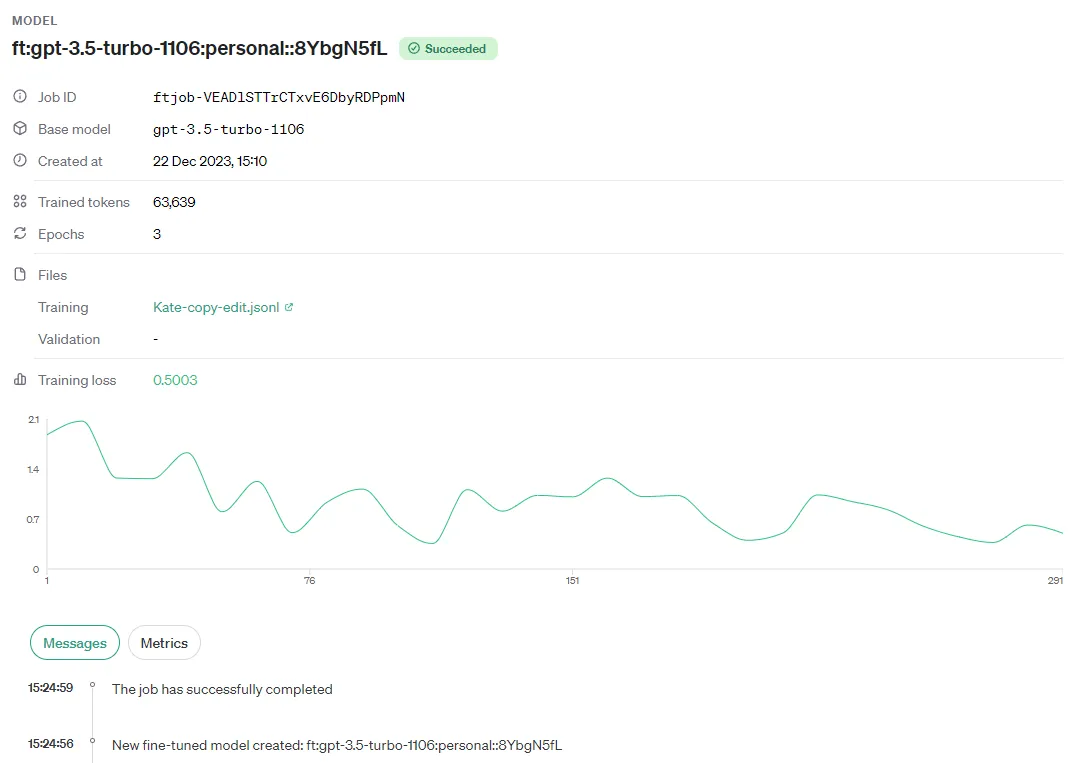
Once your file has validated, then the training will begin. The “training loss” is the overall loss at that point - the only value that matters is the end training loss.
However I always enjoy watching the curves
How to use your Fine Tune in Novelcrafter
Once your fine tune has finished training, you can use it in Novelcrafter like any other model:
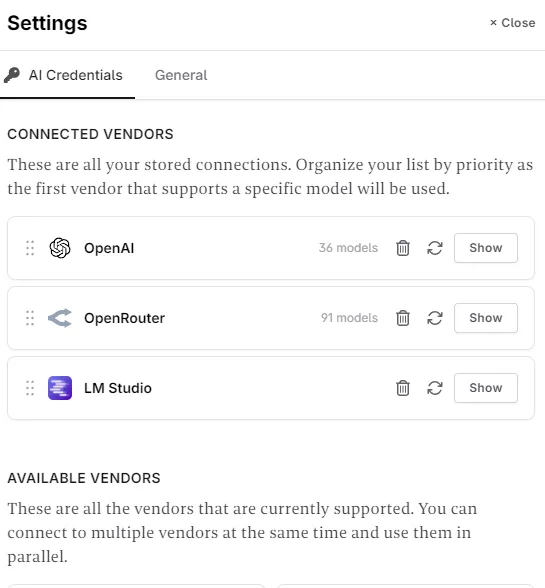
- Go to the Novelcrafter interface, then locate your Settings (under the profile/avatar menu).
- Refresh your connection to OpenAI - you will see their regular models along with your new fine tune.
- I usually then refresh my browser, just to ensure that everything is set in place.
- You can then go to the Prompts interface and add your model here:
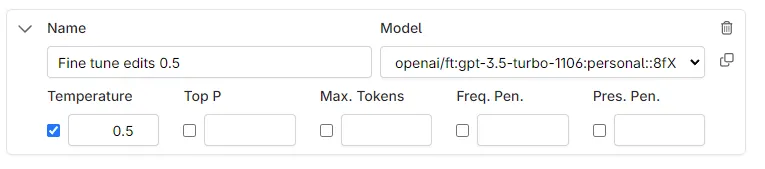
- Ensure that your system prompt matches the system prompt that you used in your fine tuning!
Frequently Asked Questions
To learn more about fine tuning in general, you can look at the OpenAI details here: Official OpenAI Fine Tuning documentation.
How many samples do I need?
OpenAI recommends at least 50 samples. We’ve found that around 75 works well in our experiments, but there is no harm in doing more/less if you find it works for you.
What does training loss mean? What is a “good” number?
This appears in the fine tune interface, and is a measure of how well the model is learning from the data. The lower the number, the better the model is learning. However, it is important to note that the training loss is not the be all and end all of a fine tune.
Based on the type of fine tune you are doing, the training loss will have a different impact:
- Prose correction: In testing we’ve found that you need a training loss of <1.0 - the lower the better. We do want the model to learn how we “rewrite” the text so you can think of this being a more strict fine tune.
- Beat to prose: Here the training loss is not as important. Somewhere around the 2 mark (10% either way) seems to work well - we don’t want it to quote our training data after all!
What Temperature/Top P/Penalty Values should I use?
Our users have found that a temperature of 0.5 is desired for the prose correction fine tune.
For the beat to prose text, I’m personally fond of generating with both 0.5 and 0.7, then kitbashing (merging multiple sources into one output) the two generations together. If you want the prose to stick closer to the beat, you can also try lowering the temperature.
Our experiments have found that you do not need to change any of the other parameters.
What if I want to use a NSFW model?
There are other platforms out there, such as Anyscale, that allow you to fine tune other models, however they have a smaller context window. A future tutorial will follow on how to do this.
How much does a Fine Tune cost?
A fine tune is generally more expensive than a regular model. Firstly, you have to pay for the actual training part, and then you have to pay for using your bespoke model.
According to the OpenAI website the cost is calculated as follows:
total cost = base cost per 1k tokens * number of tokens in the input file * number of epochs trained
For a training file with 100,000 tokens trained over 3 epochs, the expected cost would be ~$2.40 USD
| Model | Training | Input Usage | Output Usage |
|---|---|---|---|
| gpt-3.5-turbo | $0.008 / 1K tokens | $0.003 / 1K tokens | $0.006 / 1K tokens |
I have run fine tunes of >150k tokens over 3 epocs and it’s been in the $1.50 range - sometimes less, so they might not have updated that cost since the last change in pricing.
Can I delete a Fine Tune?
Yes, however, it requires coding that the author (that’s me, Kate!) doesn’t know at the point of writing this (as you can tell by the 36 connections she had…)
Kate
Based in the UK, Kate has been writing since she was young, driven by a burning need to get the vivid tales in her head down on paper… or the computer screen.
